*️⃣ 시험 출제 방식
| 과목평가 - 1시간30분 - 객관식, 주관식, 서술형 |
- 범위 : MLP, CNN, 데이터 생성 방법, 토큰화, 임베딩, PEFT - 이론을 정확히 이해하고 있다면, 문제 출제 의도를 이해하여 답변을 적을 수 있을 것이다 |
| 월말평가 - 1시간30분 - 파일제출형 (3문제) |
- 범위 : EDA, 선형회귀, RAG 기본 - 코드의 흐름을 이해하고 있으면, 스켈레톤 코드를 수정하여 완성할 수 있을 것이다 - Solution.ipynb 파일을 압축하여 제출한다 |
AI 를 위한 Python 과 Math
AI를 위한 준비과정
- 파이썬 기본 문법 ㅡ if, for, 변수, 리스트, 함수
- 클래스 ㅡ PyThorch 로 모델 제작할때 필요
- Numpy ㅡ 선형대수학, 빠른 소수점 연산
- Pandas ㅡ 데이터확인, 삭제, EDA, 전처리(필터링), csv 불러오기
- Matplot ㅡ 데이터 시각화, 기본 라이브러리
- Seabon ㅡ 데이터 시각화, Matplot 기반, Pandas 와 찰떡궁합
- 선형회귀 ㅡ (수치) y = ax + b
- 로지스틱 회귀 2️⃣ ㅡ (분류) y = sigmod(ax+b)
- Gradient Decent ㅡ 오차가 가장 적게 나오도록 a 와 b 를 조정해나가는 것
- 코드를 직접 실행해보면서 배운 내용을 리뷰
- 주요 포인트에 대해서 어떤 내용을 학습했고 왜 이걸 배웠는지 대해 리뷰
- 여기까지 AI 를 위한 Python과 Math 과목에서는 이러한 내용이 중요했습니다.
- Python
- Numpy, Pandas, Matplot 3총사
- 선형회귀 / 로지스틱 회귀 (Gradient Descent)
EDA 2️⃣
EDA (Exploratory Data Analysis) 를 통해 데이터를 잘 이해한다
- EDA : 데이터를 살펴보는 행동 ㅡ Pandas, Matplot 으로 할 수 있고, Pandas 를 쓸때는 Seaborn 을 사용헀다
- 데이터 샘블을 확인 ㅡ load_dataset()
- 필드 확인 ㅡ head()
- 기본 통계량 확인
- 분포 확인 ㅡ regplot(), heatmap(), pairplot() 으로 추세선 확인
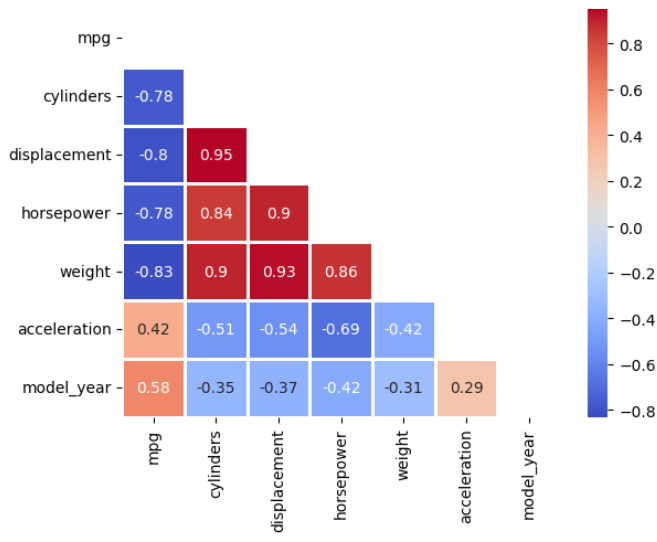
- 상관계수 확인 ㅡ 0에 가까울수록 무상관, 0에서 멀수록 비례/반비레
import seaborn as sns
df = sns.load_dataset("mpg")
df.head()
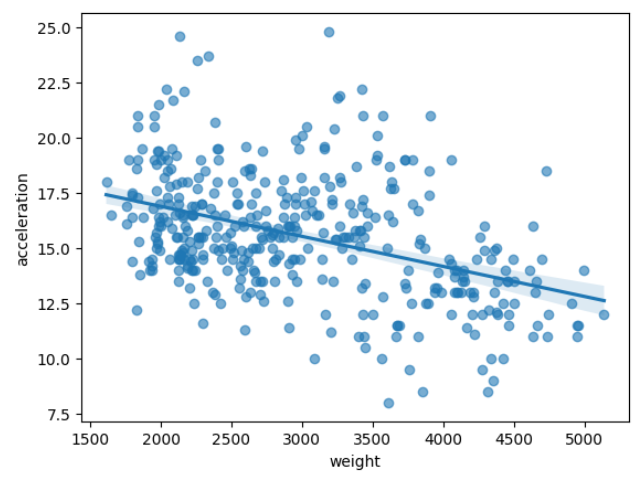
import seaborn as sns
df = sns.load_dataset("mpg")
sns.regplot(data=df, x="weight", y="acceleration", scatter_kws={'alpha':0.6})
print()import numpy as np
import seaborn as sns
df = sns.load_dataset("mpg")
corr = df.corr(numeric_only=True) # 상관계수 행렬 계산
mask = np.triu(np.ones_like(corr, dtype=bool)) # 삼각형 마스크 만들기 (상단 삼각형 가리기)
sns.heatmap(corr, mask=mask, annot=True, cmap="coolwarm", linewidths=1)
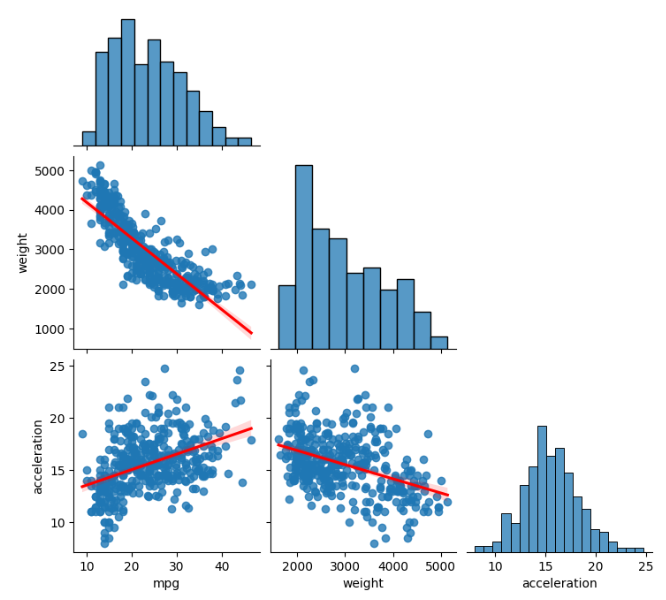
print()import seaborn as sns
import matplotlib.pyplot as plt
df = sns.load_dataset("mpg")
sns.pairplot(df[["mpg", "weight", "acceleration"]], corner=True, kind="reg", plot_kws={'line_kws': {'color': 'red'}})
print()
MLP 1️⃣
MLP (Multi-Layer Perceptron)
- 하나 이상의 은닉층을 가진 신경망
- 활성화 함수와 함께 복잡합 패턴을 학습하고 분류
- 딥러닝 학습의 시작점
- 신경망으로도 선형회귀선을 그려볼 수 있습니다.
- 어차피 추세선은 y = ax + b 로 표현될수 있고, Nueral Network도 y = Wx + b로 표현될수 있거든요
- ReLU 라는 활성화 함수를 추가하여, y = Wx + b 의 한계를 뛰어 넘었습니다.
- 함수의 중첩과 ReLU라는 활성화 함수를 이용하면, 어떤 선도 모두 모사할수 있었습니다.
- 함수의 중첩을 AI에서는 Sequantial Connection이라고 합니다.
토큰화 / 임베딩 1️⃣
- 토큰화 : 문장을 토큰 단위로 나누는 과정
- 임베딩 : 각 토큰화된 단어들에게 의미를 부여하는 과정. 의미공간의 Vector 값을 갖게 된다
- 문장은 모델에 바로 대입할 수 없었습니다~!
- 그래서 각 토큰단위로 글자를 자르고, 이를 수로 바꾸었습니다.
- 그리고 각 수를 벡터공간의 벡터값으로 치환하였습니다.
- 그리고 같은 의미를 가진 단어는 유사한 벡터값을 가지도록 밉팽해주는 "임베딩 모델"을 사용합니다.
- 임베딩 모델은 보통 트랜스포머 기반 모델로 만들곤합니다.
- 유사한 단어가 유사한 벡터값을 가지는지 확인할 수 있습니다.
합성데이터와 데이터 증강
- 합성데이터 (Synthetic Data) : 실제 세계에 없는 새로운 데이터를 생성하는 것
- 데이터증강 (Data Augmentation) : 실제 데이터를 변형하여 데이터 셋을 확보하는 것
CNN 1️⃣
CNN (Convolutional Neural Network)
- 이미지, 영사에서 시각 데이터를 특징을 기반으로 사물을 인식할 수 있는 딥러닝 알고리즘
- 2012 년 AI 겨울을 끝내고, CNN 기반의 AlexNet 을 통해 AI 시대를 다시 열게 되었음
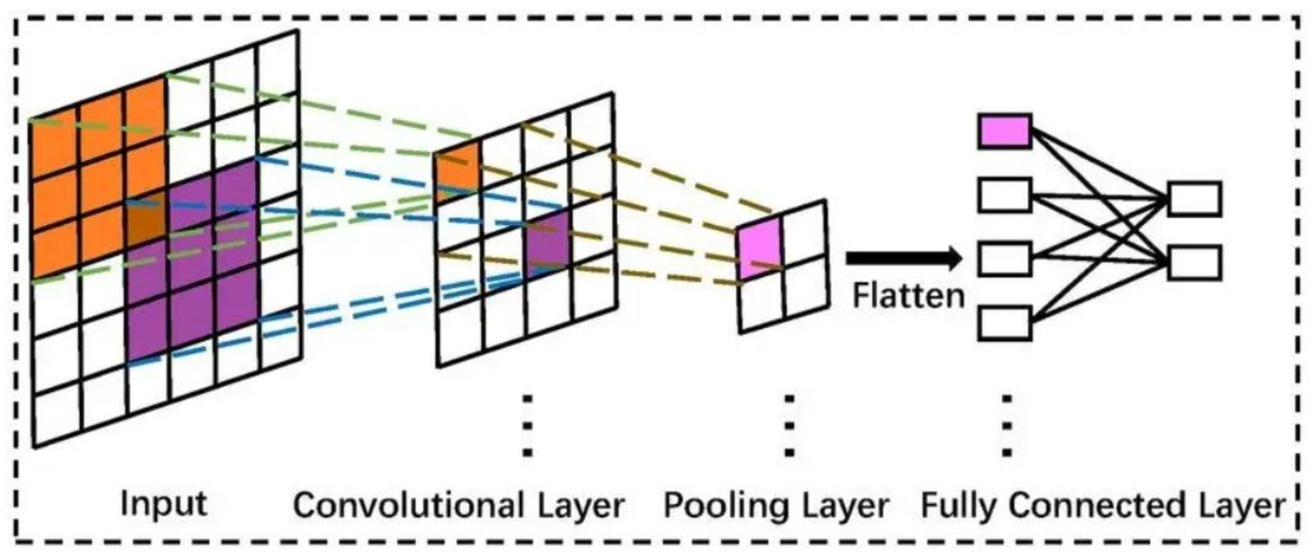
- 컨볼루션 연산으로, 테두리 추출 등 이미지의 특징을 도도라지도록 만들 수 있습니다.
- CNN은 이 커널함수의 값을 Weight로 취급하여 알아내는 것이죠.
- 이후 이렇게 특징이 뽑아진 값을 ReLU로 비선형함수로 만들구요
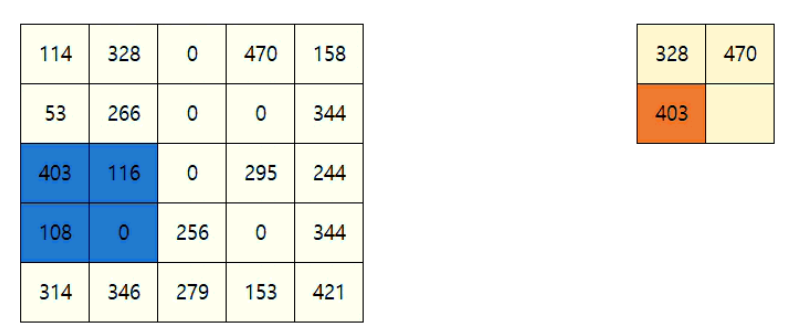
- Max Pooling을 통해, 강한 특징이 나오는 값만 뽑아냅니다.


- CNN은 다음과 같은 구조를 가졌습니다.
- Convolution 연산을 하고, Maxpooling하고, 이를 반복하고
- 마지막에는 FC : MLP를 연결해서 0 ~ 9 까지 분류할 수 있었습니다.
- 여기서 파라미터값은 다음과 같습니다. 1. 커널함수 2. FC의 Weight, bias 값들
- Gradient Decent를 통해 이 파라미터값을 알아내는 것이죠.
- CNN 원리를 살펴보고, CNN 기반인 AlexNet까지 학습하게 됩니다.

- 이후 첫 파인튜닝을 합니다
- Partial 파인튜닝중 하나인 Linear Probing을 통해 분류모델을 만들어봤습니다.
- 마지막 Layer만 새로운 Layer로 바꾸는 것이죠.
- 그리고 추가학습을통해 이 새로운 Layer의 파라미터값을 결정해줍니다.
- 다른 파라미터값은 건드리지않습니다.
- 이를 이용하면, 멋진 특징추출기(백본)을 그대로 사용하면서, 다양한 분류모델을 만들 수 있습니다.

RNN / LSTM
RNN (Recurrent Neural Network)
- AI 에서 핵심 딥러닝 알고리즘 중 하나
- 시퀀스 데이터를 학습시키고 추론시키는데 특화된 딥러닝
- Attention 의 필요성을 이해하기 위해 학습했음
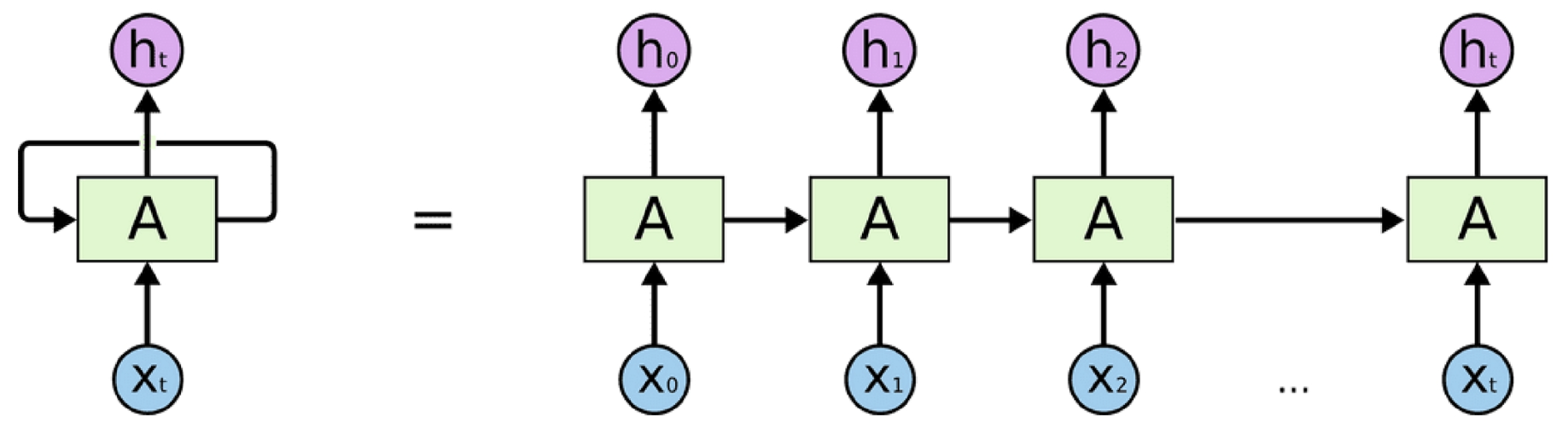
- RNN은 Hidden Layer의 마지막 출력값을 다음 Layer의 입력값으로 넣어주는 방식입니다.
- Next 토큰을 예측할 수 있는 모델이었습니다.
- RNN에는 대표적으로 두 가지 단점이 문제점이 있었는데요.
- 과거 Hidden Layer의 출력값의 정보가 점점 소실되는 문제점이 있습니다.
- 또 하나는 GD할때 필요한 Backpropagation시 미분값이 점점 0으로 수렴한다는 문제가 있습니다.
- 이로 인해 긴 문장일때 추론과, 학습이 잘안되어습니다
LSTM (Long Short-Term Memory)
- RNN의 가장 큰 단점 : 과거 정보를 오래 기억하지 못한다
- 과거 정보가 사라지는 이유 : 이전 정보를 계속 곱하면서 진행하기 때문 (기울기 소실 발생)
- LSTM 은 입력/출력/망각 게이트를 통해 중요한 정보는 기억하고 필요없는 정보는 버림 (긴 문맥도 이해할 수 있게 됨)
- LTM 의 한계점 : 문맥 내 모든 단어 간의 관계를 한번에 파악하기 어려움

Attention 과 Transformer 모델
Attention
- 입력데이터에 중요한 부분에 집중할 수 있게 돕는 기술
- 문맥을 이해하는 벡터를 만들어주는 역할을 함
- 이를 보안하기 위해 Attention 이 등장했죠.
- 임베딩 벡터 값 끼리 유사성을 비교하여, 문맥표현공간의 벡터값을 만들어내는 것이 Attention 입니다.
- Attention을 이용하면 토큰이 아닌 문장 단위로, 같은 의미의 문맥은 유사한 벡터값을 갖도록 맵핑할 수 있습니다.
- 또한 같은 의미를 가진 사진도, 유사한 벡터값을 갖도록 맵핑할 수 있습니다.
- 여러개의 attention을 더 정교하게 만든 모델이 트랜스포머모델입니다.
- 근래 모델들은 다 트랜스포머모델이죠.
Transformer
- Attention 을 encoder, decoder 형태로 활용하여 Foundation Model 시대를 열게된 딥러닝 모델
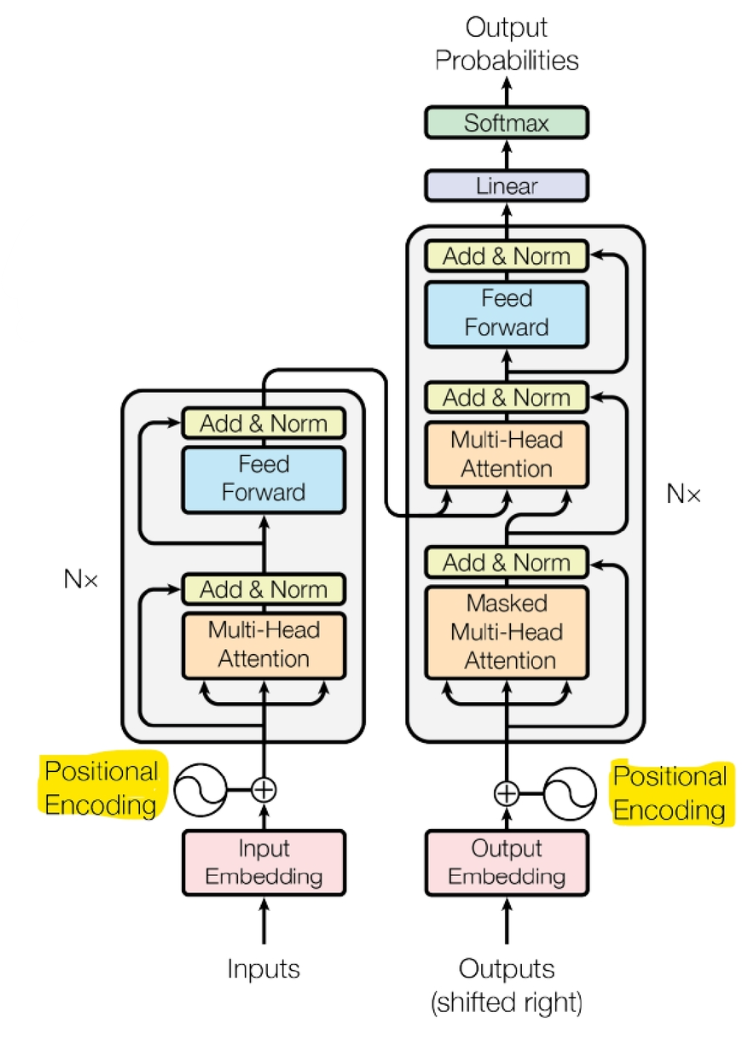
Transformer 기반 이미지 모델
- Transformer 는 텍스트, 이미지, 음성 등 여러 모달을 다루는 모델의 성능을 극대화 시킴
- CNN 대신 트랜스포머 구조를 택하면, 이미지인식 성능이 더 올라갔습니다.
- 이미지 생성도 성능이 올라갔습니다
- 이미지 생성방법인 Diffusion 알고리즘은 다음과 같이 동작했었습니다.
- 학습 : 원본 이미지에 노이즈를 조금 추가하고 어디에 얼마나 노이즈를 추가했는지 예측합니다. 이를 반복합니다.
- 추론 : 완전한 노이즈로 시작해서, 노이즈를 점점 제거하면서 복원하는 방법으로 이미지를 생성합니다.
- 이 알고리즘 역시 기존에는 CNN 기반 모델을 사용했었는데, 트랜스포머 구조로 성능이 월등히 올라갔습니다.
RAG 2️⃣
RAG (Retrieval-Augmented Generation)
- LLM 이 신뢰성 있는 최신 정보를 참고하여 답변하게 하는 기술
- 환각 현상을 줄일 수 있음
- Langchain 사용방법과 함께 RAG 구현 방법을 실습
- 이제 새로운 주제로 넘어갑니다.
- LLM을 활용한 AI App을 만드는 LangChain과 RAG 기술을 학습합니다.
- RAG는 AI Workflow를 만드는 툴로 시작되었습니다
- 다양한 응용 사례가 있지만, 기업에서도 자주 사용되는 RAG 기술에 대해 알아보았습니다.
- RAG는 간단합니다!
- LLM에게 바로 프롬프트를 넣는 것이 아니고,
- 구글링 한번하고 그 결과와 함께 LLM에 입력으로 넣는것이 RAG 기술이죠
- 꼭 임베딩 벡터를 거친 벡터값만 검색해야하는 건아닙니다.
- 진짜 검색엔진에서 검색결과를 넣어줘도 RAG 입니다.
- RAG를 써야하는 이유는, 정확도가 더 올라가죠.
- LLM이 아직 학습하지 못한 최신정보를 알고 답변할 수 있습니다.
- 준비 단계
- 1. 사내 문서 Text로 추출하여, "Chunk" 라는 단락 단위로 나눕니다.
- 2. "Chunk" 를 임베딩모델의 입력값으로 넣어, 벡터로 만들고 만듭니다.
- 3. 벡터를 DB에 저장합니다.
- Workflow 동작
- 4. 질문 프롬프트를 입력 받습니다.
- 5. 임베딩 모델을 거쳐 벡터 값을 얻어낸 후, Retriever로 유사한 Chunk를 검색합니다.
- 6. 기존 질문과, 검색결과를 합쳐 프롬프트를 완성합니다.
- 7. 프롬프트를 LLM에 입력으로 넣습니다.
- 8. 더 멋진 결과가 나옵니다.
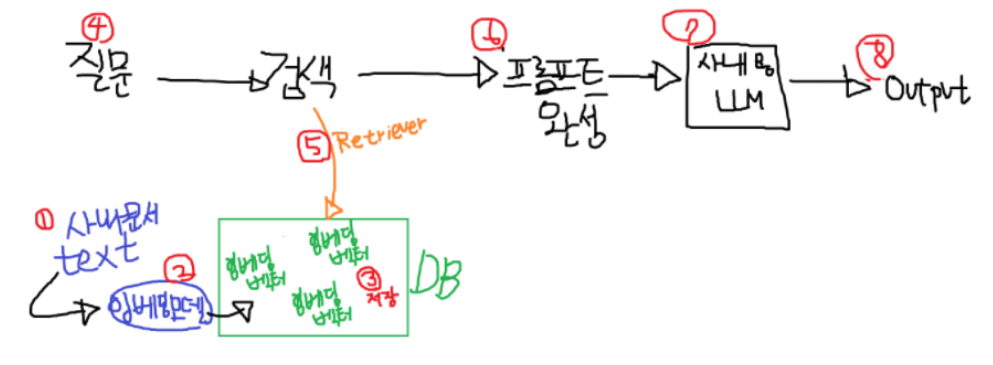
- LangChain으로는 다음과 같은 원리고 개발됩니다.

# - 검색할 Text를 준비합니다.
%%writefile shipping_policy.txt
========================
AI 온라인 서점 배송 정책
========================
[일반 배송]
평일 오후 3시 이전 주문 시 당일 발송됩니다.
오후 3시 이후 주문 건은 익일 발송됩니다.
주말 및 공휴일은 배송이 어렵습니다.
도서 산간 지역 배송
제주 및 도서 산간 지역은 추가 배송비 3,000원이 발생할 수 있습니다.
[배송 조회]
배송 관련 문의는 고객센터(1588-0000)로 연락 주시기 바랍니다.
==============
배송 파손 정책
==============
상품이 배송 중 파손된 경우, 즉시 새 상품으로 교환해드립니다.
제품 이상이 확인되면 왕복 배송비는 전액 당사 부담입니다.
수령 후 7일 이내에 고객센터로 연락해 주셔야 합니다.
파손된 상품과 포장 상태 사진을 함께 제출해 주세요.
확인 후, 새 상품을 발송하거나 환불 절차를 진행합니다.
단순 변심이나 부주의로 인한 손상은 교환 대상이 아닙니다.# - 이제 Text를 청킹합니다.
from langchain_community.document_loaders.text import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1. Load: 텍스트 파일 불러오기
loader = TextLoader("./shipping_policy.txt", encoding="utf-8")
documents = loader.load()
print("--- 원본 문서 ---")
print(documents[0].page_content)
# 2. Split: 문서를 200자 단위로 자르기 (엔터 단위, 40자씩 겹치게)
splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=40)
chunks = splitter.split_documents(documents)
print("\n--- 200자 단위로 잘린 문서 조각(Chunk)들 ---")
for i, chunk in enumerate(chunks):
print(f"[Chunk {i+1}]")
print(chunk.page_content)
print()
print()# - Text를 임베딩 모델을 거쳐 vector로 만들고, VectorDB에 저장합니다.
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 잘라낸 문서 조각(chunks)들을 임베딩하여 Vector DB에 저장합니다.
vector_store = Chroma(
embedding_function=embeddings,
persist_directory="./chroma_store",
)
vector_store.add_documents(chunks)
print("Chunk들을 Vector DB에 저장 완료")# - 검색기 생성 후 테스트 해봅니다.
retriever = vector_store.as_retriever()
question = "주말에도 배송해주나요?"
retrieved_docs = retriever.invoke(question)
print(f"[질문]: {question}")
print(f"\n[검색 결과]:\n{retrieved_docs[0].page_content}")# - RAG를 구현합니다.
# - Chain 코드를 보면, Workflow를 확인할 수 있습니다.
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# LLM 모델을 준비합니다.
model = init_chat_model("openai:gpt-4o-mini")
# LLM에게 어떤 역할을 할지 알려주는 프롬프트(지시서)를 만듭니다.
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 AI 온라인 서점의 친절한 고객 서비스 담당자입니다. 주어진 정보를 바탕으로 사용자의 질문에 답변해주세요."),
("user", "[질문]: {question}\n\n[참고 정보]: {context}"),
])
# RAG 체인(Chain)을 만듭니다.
rag_chain = (
{
"context": retriever, # 컴포넌트 1 : 전달받은 입력값(question_input1, 2)을 vector db에 검색 후 검색결과를 반환
"question": RunnablePassthrough() # 컴포넌트 2 : 전달받은 입력값(question_input1, 2)을 그대로 반환
}
| prompt # 컴포넌트 3 : {context, question} 딕셔너리가 입력되면, 완성된 프롬프트를 반환
| model # 컴포넌트 4 : 완성된 프롬프트를 LLM에 전달, 완성된 프롬프트를 반환
| StrOutputParser() # 컴포넌트 5. LLM이 반환한 정보 중, Text 답변만 문자열로 반환
)
print("RAG 체인 준비 완료!")
print("----------------------------")
print()
print()
# RAG 체인에 질문을 던져봅니다.
question_input1 = "주말 배송에 대해 알려주세요."
answer1 = rag_chain.invoke(question_input1)
print(f"[질문 1]: {question_input1}")
print(f"[답변 1]: {answer1}")
print()
print()
print("----------------------------")
print()
print()
question_input2 = "제주도로 보내면 배송비가 추가되나요?"
answer2 = rag_chain.invoke(question_input2)
print(f"[질문 2]: {question_input2}")
print(f"[답변 2]: {answer2}")#- 이후 멀티턴과 ReAct 구조 개념과 구현 방법을 살펴보았습니다.
# - 다음은 멀티턴 코드입니다.
# - 과거의 정보를 가지고 대화를 하는 것이죠
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# =============================================
# 2개의 체인 구성
# =============================================
prompt = ChatPromptTemplate.from_template(
"""
넌 최고의 미식가야
매우 사랑스럽고, 한 문장으로만 대답하지.
[지금까지의 대화] :
{history}
[질문] :
{input}
"""
)
model = init_chat_model("openai:gpt-4o-mini")
parser = StrOutputParser()
chain = prompt | model | parser
# =============================================
# 대화 히스토리 저장
# =============================================
history = []
def chat(user_input):
"""한 턴의 대화를 수행하고 history에 추가"""
# History List를 하나의 문자열로 변경
formatted_history = "\n".join([f"{m['role']}: {m['content']}" for m in history])
# Chain 시작! (LLM 답변 출력됨)
response = chain.invoke({"input": user_input, "history": formatted_history})
# History List에 질문과 대화 추가하기
history.append({"role": "user", "content": user_input})
history.append({"role": "assistant", "content": response})
return response
# =============================================
# 대화 쉘
# =============================================
print("🍔 미식가 챗봇에 오신 걸 환영합니다!")
print("대화를 종료하려면 'bye'를 입력하세요.\n")
while True:
user_input = input("👤 인간 : ")
ai_reply = chat(user_input)
print(f"🤖 미식가 AI : {ai_reply}\n")
if user_input == 'bye':
break- ReAct 구조로 목적을 이룰 때 까지 툴을 사용하는 기능을 구현할 수 있습니다.

from dataclasses import dataclass
from langchain.agents.middleware import SummarizationMiddleware # 요약 기능추가
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
# =====================================================
# 시스템 프롬프트
# =====================================================
SYSTEM_PROMPT = """너는 최고의 미식가야, 항상 간결하게 말하지
사용자가 요청하면 필요한 도구를 정확히 한 번만 사용하고
너에게는 세 개의 도구가 있어:
1. add_sum(a, b)
- 두 수의 합을 구합니다.
2. add_minus(a, b)
- 두 수의 차를 구합니다.
3. add_multiply(a, b)
- 두 수의 곱을 구합니다.
결과를 이용해 농담 섞인 대답으로 답해줘.
"""
# =====================================================
# 도구 정의
# =====================================================
@tool
def add_sum(a: int, b: int) -> int:
"""두 수의 합을 구합니다."""
return a + b
@tool
def add_minus(a: int, b: int) -> int:
"""두 수의 차를 구합니다."""
return a - b
@tool
def add_multiply(a: int, b: int) -> int:
"""두 수의 곱을 구합니다."""
return a * b
@tool
def get_weather() -> str:
"""오늘의 날씨를 반환합니다."""
# API 호출 코드 삽입
return "허리케인"
tool = [add_sum, add_minus, add_multiply, get_weather]
# =====================================================
# 모델 설정
# =====================================================
model = init_chat_model("openai:gpt-4o-mini")
# =====================================================
# 최종 결과 포맷
# =====================================================
@dataclass
class ResponseFormat:
answer: str # AI의 대답 문장
# =====================================================
# 멀티턴을 위한 InMemorySaver
# =====================================================
checkpointer = InMemorySaver()
# =====================================================
# Agent 생성 (이곳에 SummarizationMiddleware를 설치합니다.)
# =====================================================
agent = create_agent(
model=model,
system_prompt=SYSTEM_PROMPT,
tools=tool,
response_format=ResponseFormat,
middleware=[
SummarizationMiddleware(
model="openai:gpt-4o-mini", # 요약을 담당할 모델
max_tokens_before_summary=4000, # 최대 4000 토큰으로 요약합니다.
messages_to_keep=20, # 요약 이후 최대 20 메세지는 유지합니다.
)],
checkpointer=checkpointer
)
# =====================================================
# 실행 예시 (이쁘게 출력하려는 노력입니다.)
# =====================================================
def print_message(msgs):
for msg in msgs:
if hasattr(msg, "tool_calls") and msg.tool_calls:
for tool_call in msg.tool_calls:
name = tool_call.get("name")
args = tool_call.get("args")
if name == "ResponseFormat":
continue
print(f"💭( 🛠️{name} 함수 호출 {args} )")
if "AIMessage" not in str(type(msg)):
print(f"💭( {type(msg).__name__} : {msg.content!r} )")
# =============================================
# 대화 루프 (멀티턴)
# =============================================
print("AI Agent 챗봇에 오신 걸 환영합니다!")
print("대화를 종료하려면 'bye'를 입력하세요.\n")
print(f"🤖 AI Agent : 무엇이든 질문하세요")
# thread_id를 통해 대화 세션 유지 (필수)
config = {"configurable": {"thread_id": "kfc_user"}}
while True:
print()
user_input = input("👤 인간 : ")
response = agent.invoke({
"messages": [
{"role": "user", "content": user_input}
]},config = config) # thread_id 단위로 대화 상태 저장
print_message(response["messages"][1:-1])
print(f"🤖 AI Agent : {response["structured_response"].answer}")
if user_input == 'bye':
breakPEFT 1️⃣
PEFT (Parameter-Efficient Fine-Tuning)
- 효율적인 파인튜닝
- 모든 파라미터를 변경하지 않고, 일부 파라미터만 변경하여 파인튜닝의 효율을 극대화시킴
- LoRA 를 중심적으로 다룸
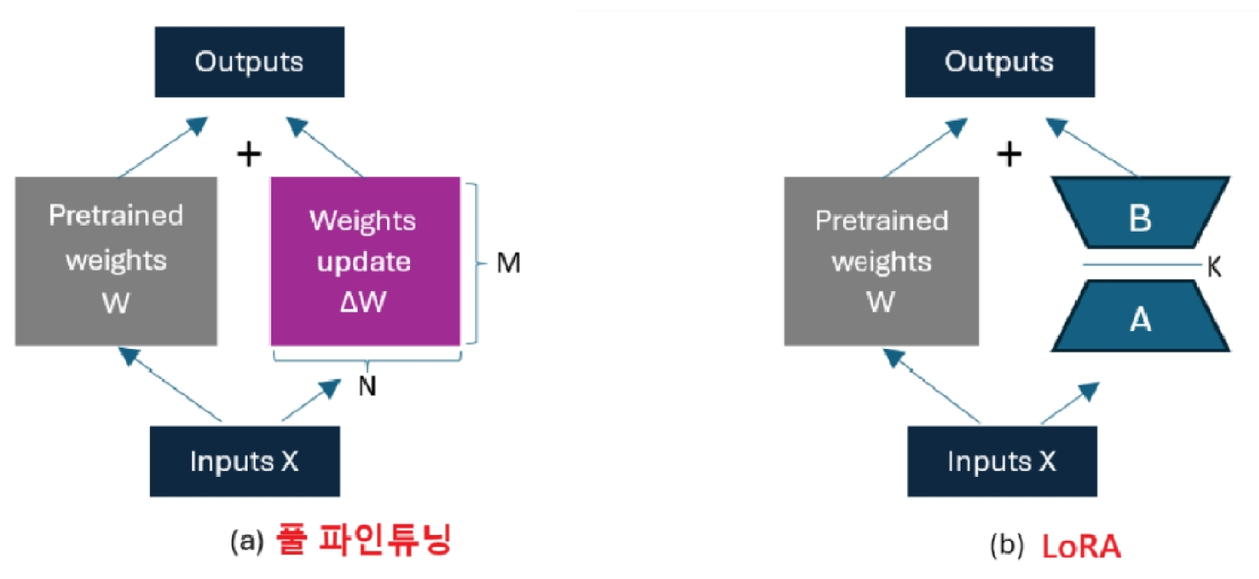
- 효율적으로 파인튜닝을 하는 방법인 LoRA를 학습하고, 양자화의 개념을 배웁니다.
- LoRA는 Delta W 를 A, B 의 저랭크의 연산으로 근사한 Delta W 를 찾아내는 방법입니다.
- 이 방법으로 적은량의 파라미터 학습으로 풀 파인튜닝 효과를 낼 수 있었습니다.
- 실습은 Unsloth Library를 사용했습니다.
- Unsloth Library는 저성능, 적은 개수의 GPU로 파인튜닝을 가능하도록 만든 Library 입니다.
- 허깅페이스 Transformer Library 처럼 추론도 가능합니다.
- 허깅페이스 Transformer Library 쓰는 것 보다 LoRA 학습 효율이 더 좋다고 합니다.
- (공식홈페이지 설명에 따르면)
- **2배 이상 학습속도가 빠름**
- **70% 이상 GPU 메모리 사용량이 줄어듬**
- 비교 대상은 허깅페이스의 Flash Attention 2 가속화 옵션 대비입니다.
- 그런데 구글 코랩의 T4 GPU에서는 Flash Attention 2 가속화 옵션도 못쓰거든요. (유료 GPU만 사용 가능)
- 그래서 코랩 사용자한테는 Unsloth의 의미가 더더욱 커요
데이터 생성 방법 1️⃣
선형 회귀 2️⃣
import numpy as np
import plotly.graph_objects as go
# =====================================================
# 1. 데이터 준비 (y = 2x + 1 + noise)
# =====================================================
np.random.seed(0)
x = np.linspace(0, 10, 50)
y = 2 * x + 1 + np.random.randn(50) * 2
def mse(a, b):
y_pred = a * x + b
return np.mean((y - y_pred) ** 2)
# =====================================================
# 2. 손실 곡면
# =====================================================
a_range = np.linspace(0, 4, 80)
b_range = np.linspace(-2, 4, 80)
A, B = np.meshgrid(a_range, b_range)
Z = np.array([[mse(a, b) for a in a_range] for b in b_range])
# =====================================================
# 3. 경사하강법
# =====================================================
a, b = 0.0, 0.0
lr = 0.025
steps = 100
path = [(a, b, mse(a, b))]
for _ in range(steps):
y_pred = a * x + b
da = -2 * np.mean(x * (y - y_pred))
db = -2 * np.mean(y - y_pred)
a -= lr * da
b -= lr * db
path.append((a, b, mse(a, b)))
path = np.array(path)
# =====================================================
# 4. 그래프 기본 세팅
# =====================================================
fig = go.Figure()
# 손실 곡면
fig.add_trace(go.Surface(
x=A, y=B, z=Z,
colorscale='Viridis',
opacity=0.8,
showscale=False
))
# 초기점
fig.add_trace(go.Scatter3d(
x=[path[0,0]],
y=[path[0,1]],
z=[path[0,2] - 80],
mode='text',
text=["🏃♂️"],
textfont=dict(size=30),
name='Runner'
))
# =====================================================
# 5. 프레임 생성 (Surface + Path)
# =====================================================
frames = []
for i in range(1, len(path)):
frames.append(go.Frame(
data=[
go.Surface(
x=A, y=B, z=Z,
colorscale='Viridis',
opacity=0.8,
showscale=False
),
go.Scatter3d(
x=path[:i,0],
y=path[:i,1],
z=path[:i,2],
mode='lines+markers',
line=dict(color='red', width=6),
marker=dict(size=4, color='red')
)
]
))
# =====================================================
# 6. 애니메이션 설정
# =====================================================
fig.update_layout(
title="🎯 Gradient Descent Converging on 3D Loss Surface",
width=500, height=500,
template='plotly_white',
scene=dict(
xaxis_title='a (slope)',
yaxis_title='b (intercept)',
zaxis_title='Loss',
xaxis=dict(range=[-1, 4]),
yaxis=dict(range=[-1, 2]),
zaxis=dict(range=[0, 250]),
camera=dict(eye=dict(x=1.5, y=1.5, z=1.2))
),
updatemenus=[{
"type": "buttons",
"buttons": [
{"label": "▶ Play (Slow)",
"method": "animate",
"args": [None, {
"frame": {"duration": 500, "redraw": True},
"transition": {"duration": 0},
"fromcurrent": True
}]},
{"label": "⏸ Pause",
"method": "animate",
"args": [[None], {
"frame": {"duration": 0, "redraw": False},
"mode": "immediate"
}]}
]
}]
)
fig.frames = frames
fig.show()'【2025】 SSAFY14 > [이론] Python' 카테고리의 다른 글
| [DB] 1,2. SQL (0) | 2025.11.06 |
|---|---|
| [AI] 11-2. AI 강의 Wrap UP 2 - 관통PJT에 AI 적용하기 (0) | 2025.11.02 |
| [AI] 10. AI 모델 활용 - 양자화⚠️ (0) | 2025.11.02 |
| [AI] 9. Mastering AI Agent⚠️ (0) | 2025.11.02 |
| [AI] 8. 파인튜닝 및 AI 모델 활용🔖 - 양자화, LoRA (0) | 2025.11.02 |